


Optimisation des performances de MySQL : Conseils pour des requêtes de base de données plus rapides

Introduction :
Dans le monde numérique d’aujourd’hui, les bases de données jouent un rôle crucial dans la gestion des informations. MySQL, en tant que l’un des systèmes de gestion de bases de données les plus populaires, est largement utilisé pour stocker, récupérer et manipuler des données. Cependant, avec l’augmentation constante du volume de données, il est essentiel d’optimiser les performances de MySQL pour garantir des requêtes de base de données plus rapides et plus efficaces.
Cet article vise à fournir des conseils pratiques et des solutions pour optimiser les performances de MySQL. Que vous soyez un développeur débutant ou expérimenté, ces conseils vous aideront à améliorer la vitesse et l’efficacité de vos requêtes de base de données. De la gestion du fichier de configuration my.cnf à l’optimisation des requêtes et des jointures, nous couvrirons une gamme de techniques que vous pouvez utiliser pour améliorer les performances de MySQL.
Alors, commençons notre voyage vers des requêtes de base de données plus rapides et plus efficaces avec MySQL !
Gestion du fichier my.cnf
Le fichier my.cnf est un fichier de configuration qui contient des paramètres ayant un impact direct sur les performances de MySQL. Il est généralement situé dans le répertoire d’installation de MySQL et peut être modifié avec un éditeur de texte2. Voici quelques directives que vous pouvez modifier pour optimiser les performances :
– max_connections : Définit le nombre maximum de connexions simultanées à MySQL.
– thread_cache_size : Définit le nombre de threads que le serveur doit garder en cache pour une utilisation ultérieure.
– table_open_cache : Indique le nombre de tables que le serveur garde ouvertes.
– innodb_buffer_pool_size et innodb_buffer_pool_instances : Ces paramètres sont liés à la gestion de la mémoire pour InnoDB.
Il est important de noter que toute modification du fichier my.cnf nécessite un redémarrage du serveur MySQL pour que les changements prennent effet.
Vérification des moteurs de stockage MySQL et de la conception du schéma
MySQL utilise une architecture de moteur de stockage enfichable qui permet à différents moteurs de stockage d’être chargés dans un serveur MySQL en cours d’exécution. Pour déterminer quels moteurs de stockage votre serveur prend en charge, vous pouvez utiliser l’instruction SHOW ENGINES.
Chaque moteur de stockage a ses propres avantages et inconvénients, et certains sont mieux adaptés à certains types de charges de travail. Par exemple, InnoDB est un moteur de stockage transactionnel qui offre des fonctionnalités telles que le verrouillage au niveau des lignes et les clés étrangères. MyISAM est un autre moteur de stockage couramment utilisé qui est plus simple et généralement plus rapide, mais qui ne prend pas en charge les transactions.
Pour vérifier le moteur de stockage utilisé par une table spécifique, vous pouvez utiliser l’instruction SHOW CREATE TABLE ou interroger le schéma d’information.
La conception du schéma de votre base de données est également cruciale pour les performances. Une bonne conception du schéma peut minimiser la quantité de données lues du disque et donc accélérer vos requêtes. Cela comprend des considérations telles que le choix des types de données appropriés, la normalisation des données et l’utilisation efficace des index.
Utilisation des index et des partitions
Les index en MySQL sont des structures de données qui améliorent la vitesse des opérations de récupération de données sur une base de données. Ils fonctionnent de manière similaire à un index dans un livre, permettant à la base de données de trouver des données sans avoir à parcourir chaque ligne de chaque table et d’améliorer les performances des requêtes.
La partition de tables est une fonctionnalité de MySQL qui peut être utilisée pour diviser une table en plusieurs sous-tables plus petites. Chaque sous-table est appelée une partition et peut être traitée individuellement. Cela peut améliorer les performances en permettant à MySQL de ne parcourir que les partitions pertinentes lors de l’exécution d’une requête.
Voici un exemple de l’utilisation des index et des partitions dans MySQL:

Dans cet exemple, un index combiné a été créé sur dimension et date pour optimiser les requêtes basées sur ces deux colonnes.
Pour améliorer davantage les performances, vous pouvez ajouter une partition par mois à cette table en utilisant la commande ALTER TABLE:
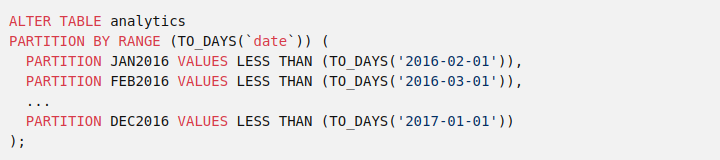
Avec la partition en place, MySQL peut d’abord déterminer quelles partitions peuvent contenir les données recherchées (c’est ce qu’on appelle la “partition pruning”), puis appliquer la requête aux sous-tables pertinentes en utilisant l’index approprié.
L’utilisation de partitions dans MySQL est transparente pour les requêtes SELECT. Vous n’avez pas besoin de modifier vos requêtes pour tenir compte des partitions. Lorsque vous exécutez une requête SELECT, MySQL détermine automatiquement quelles partitions contiennent les données nécessaires et n’interroge que ces partitions.
Par exemple, si vous avez partitionné votre table analytics par mois comme dans l’exemple précédent, et que vous exécutez une requête pour obtenir des données pour un mois spécifique, MySQL n’interrogera que la partition correspondante.
Voici un exemple de requête SELECT :

Dans cet exemple, MySQL n’interrogera que la partition FEB2016, ce qui peut améliorer considérablement les performances si votre table contient des données pour plusieurs années.
L’utilisation de partitions n’est pas limitée aux dates. MySQL supporte plusieurs types de partitionnement :
Partitionnement RANGE : Ce type de partitionnement est basé sur la plage de valeurs d’une colonne donnée. L’exemple que j’ai donné précédemment, où nous avons partitionné les données en fonction de la date, est un exemple de partitionnement RANGE.
Partitionnement LIST : Ce type de partitionnement est similaire au partitionnement RANGE, mais il est basé sur une liste de valeurs spécifiques plutôt que sur une plage de valeurs.
Partitionnement HASH : Ce type de partitionnement utilise une fonction de hachage sur la colonne de partitionnement pour déterminer la partition dans laquelle une ligne donnée doit être stockée.
Partitionnement KEY : Ce type de partitionnement est similaire au partitionnement HASH, mais il utilise la fonction de hachage MySQL pour déterminer la partition.
Partitionnement COLUMNS : Ce type de partitionnement permet de partitionner une table en fonction de plusieurs colonnes.
Donc, bien que l’exemple que j’ai donné précédemment utilise des dates pour le partitionnement, vous pouvez utiliser n’importe quelle colonne ou ensemble de colonnes pour le partitionnement en fonction de vos besoins spécifiques.
NB:
La fonctionnalité de partitionnement des tables est disponible dans MySQL à partir de la version 5.5. Cependant, il est important de noter que le support du partitionnement dans MySQL 8.0 est fourni par les moteurs de stockage InnoDB et NDB. MySQL 8.0 ne supporte actuellement pas le partitionnement des tables utilisant un moteur de stockage autre que InnoDB ou NDB, comme MyISAM
Optimisation des requêtes
L’optimisation des requêtes est un aspect essentiel de la gestion des performances de MySQL. Pour rendre une requête SELECT plus rapide, la première chose à vérifier est si vous pouvez ajouter un index. Il est recommandé de créer des index sur les colonnes utilisées dans la clause WHERE pour accélérer l’évaluation, le filtrage et la récupération finale des résultats.
L’optimisation des requêtes est un aspect essentiel de la gestion des performances de MySQL. Voici quelques exemples d’optimisation des requêtes:
1- Utilisation d’index :
Les index en MySQL sont des structures de données qui améliorent la vitesse des opérations de récupération de données sur une base de données. Sans un index, MySQL doit parcourir toute la table pour localiser les lignes pertinentes.
Par exemple, si vous avez une table users avec des colonnes id, name, et email, et que vous voulez trouver un utilisateur par son email, vous pouvez créer un index sur la colonne email pour accélérer cette recherche.
Voici comment vous pouvez créer un index sur la colonne email :

Et voici comment vous pouvez utiliser cet index dans une requête :

Dans cette requête, MySQL utilise l’index idx_users_email pour trouver rapidement l’utilisateur avec l’email ‘[email protected]’, au lieu de parcourir toutes les lignes de la table users.
2- Minimiser la quantité de données récupérées :
Par exemple, si vous n’avez besoin que de récupérer une colonne d’une table, n’utilisez pas ‘SELECT *’. Cela permet de minimiser la quantité de données récupérées et d’améliorer les performances.
3- Éviter les scans complets de table :
Un scan complet de table se produit lorsque MySQL doit parcourir toute la table pour exécuter une requête. Cela peut être lent, surtout si la table est grande. Il existe plusieurs techniques pour éviter les scans complets de table :
Utiliser des index : Comme expliqué ci-dessus, les index peuvent aider MySQL à trouver rapidement les lignes pertinentes sans avoir à parcourir toute la table.
Utiliser la clause LIMIT : Si vous savez combien de lignes vous attendez en retour, vous pouvez utiliser la clause LIMIT pour dire à MySQL de s’arrêter après avoir trouvé un certain nombre de lignes.
Maintenir les statistiques de table à jour : Vous pouvez utiliser l’instruction ANALYZE TABLE pour mettre à jour les statistiques de table, ce qui aide l’optimiseur de MySQL à choisir le meilleur plan d’exécution pour vos requêtes.
Utiliser des astuces d’optimisation : Par exemple, vous pouvez utiliser l’option –max-seeks-for-key lors du démarrage de mysqld pour dire à l’optimiseur de supposer qu’aucun scan de clé ne provoque plus de 1 000 recherches de clés.
4- Isoler et optimiser toute partie de la requête qui prend un temps excessif :
Par exemple, en fonction de la structure de la requête, une fonction pourrait être appelée une fois pour chaque ligne du résultat, ou même une fois pour chaque ligne de la table, ce qui amplifie toute inefficacité.
5- Utilisation de l’instruction EXPLAIN :
Vous pouvez utiliser l’instruction EXPLAIN pour déterminer quels index sont utilisés pour un SELECT. Par exemple, si vous avez une table film_actor et que vous voulez savoir comment MySQL exécute une requête, vous pouvez utiliser EXPLAIN :

Cela vous donnera des informations sur la façon dont MySQL exécute la requête, y compris les index utilisés, le nombre de lignes analysées, etc.
Ces exemples ne sont que quelques-unes des nombreuses techniques d’optimisation des requêtes disponibles dans MySQL. Il est toujours préférable de tester différentes approches pour voir ce qui fonctionne le mieux dans votre cas spécifique.
Utilisation du cache de requêtes
Le cache de requêtes MySQL est une fonctionnalité qui stocke le texte d’une instruction SELECT ainsi que le résultat correspondant qui a été envoyé au client. Si une instruction identique est reçue ultérieurement, le serveur récupère les résultats à partir du cache de requêtes plutôt que de parser et d’exécuter à nouveau l’instruction. Cela peut améliorer les performances en réduisant le temps nécessaire pour exécuter les requêtes fréquemment utilisées.
Supposons que vous ayez une table tshirts avec plusieurs colonnes, et qu’un utilisateur recherche des t-shirts verts. La requête pourrait ressembler à ceci :

Si le cache de requêtes est activé, MySQL vérifiera d’abord le cache de requêtes pour cette requête exacte. Si la requête a déjà été exécutée et que son résultat est stocké dans le cache, MySQL renverra le résultat à partir du cache plutôt que d’exécuter à nouveau la requête.
Vous pouvez vérifier l’utilisation du cache de requêtes en utilisant l’instruction SHOW STATUS :

Cela vous donnera des informations sur l’utilisation du cache de requêtes, y compris le nombre de requêtes insérées dans le cache (Qcache_inserts), le nombre de requêtes qui ont été servies à partir du cache (Qcache_hits), et plus encore1.
Il est important de noter que le cache de requêtes n’est pas toujours bénéfique. Par exemple, si une table est fréquemment mise à jour, le cache de requêtes pour cette table sera fréquemment invalidé, ce qui peut réduire l’efficacité du cache de requêtes. Par conséquent, il est important de surveiller l’utilisation du cache de requêtes et d’ajuster sa taille en fonction de vos besoins spécifiques.
Optimisation des jointures
L’optimisation des jointures est une technique importante pour améliorer les performances des requêtes MySQL. Voici quelques exemples :
1- Utilisation de INNER JOIN :
Supposons que vous ayez trois tables : route, flight et aircraft. Vous pouvez utiliser INNER JOIN pour récupérer des données de ces trois tables :

Dans cet exemple, MySQL utilise ses algorithmes d’optimisation pour exécuter la requête plus rapidement1.
2- Conversion d’une jointure externe en une jointure interne :
Dans certains cas, vous pouvez convertir une jointure externe en une jointure interne pour améliorer les performances. Par exemple, si vous avez deux tables t1 et t2, et que vous exécutez la requête suivante :

Si t2.column1 est NULL, la clause WHERE serait fausse. Par conséquent, vous pouvez convertir la requête en une jointure interne :

Ces exemples illustrent comment l’optimisation des jointures peut améliorer les performances des requêtes MySQL. Cependant, il est important de noter que l’optimisation des jointures dépend de nombreux facteurs, y compris la structure de vos tables, les index disponibles et la nature spécifique de vos requêtes.
Utilisation de recherches en texte intégral
La recherche en texte intégral est une fonctionnalité puissante de MySQL qui permet de rechercher des données textuelles de manière plus flexible et naturelle. Voici un exemple d’utilisation de la recherche en texte intégral:
Supposons que vous ayez une table articles avec une colonne content qui contient du texte. Vous pouvez créer un index FULLTEXT sur la colonne content comme suit :

Une fois l’index FULLTEXT créé, vous pouvez effectuer une recherche en texte intégral en utilisant la syntaxe MATCH…AGAINST

Dans cette requête, MATCH (content) spécifie la colonne sur laquelle effectuer la recherche, et AGAINST (‘database engine’ IN NATURAL LANGUAGE MODE) spécifie la chaîne de recherche et le mode de recherche.
Dans ce cas, le mode de recherche est IN NATURAL LANGUAGE MODE, ce qui signifie que MySQL interprète la chaîne de recherche comme une phrase en langage naturel. MySQL cherche des lignes qui contiennent les mots “database” et “engine”, indépendamment de l’ordre dans lequel ils apparaissent.
La recherche en texte intégral peut également renvoyer un score de pertinence pour chaque ligne, qui indique à quel point la ligne correspond à la chaîne de recherche. Vous pouvez utiliser ce score pour trier les résultats de la recherche :

Dans cette requête, MATCH (content) AGAINST (‘database engine’) AS relevance crée une colonne virtuelle relevance qui contient le score de pertinence, et ORDER BY relevance DESC trie les résultats en fonction de ce score.
Optimisation des instructions Like avec la clause Union
Pour optimiser les requêtes avec UNION, il est recommandé d’utiliser UNION ALL au lieu de UNION si vous êtes sûr qu’il n’y aura pas de doublons dans les jeux de données joints. Cela est dû au fait que UNION supprime les doublons, ce qui peut entraîner une surcharge de traitement. En revanche, UNION ALL ne supprime pas les doublons, ce qui peut améliorer les performances.
L’optimisation des instructions LIKE avec la clause UNION peut être utile lorsque vous recherchez des données qui correspondent à plusieurs modèles. Voici un exemple :
Supposons que vous ayez une table products avec une colonne name. Vous voulez trouver tous les produits dont le nom contient “apple” ou “banana”. Vous pouvez utiliser LIKE avec UNION pour cela :

Dans cet exemple, la première requête SELECT trouve tous les produits dont le nom contient “apple”, et la deuxième requête SELECT trouve tous les produits dont le nom contient “banana”. La clause UNION combine les résultats des deux requêtes.
Notez que UNION supprime les doublons des résultats. Si vous voulez inclure les doublons, vous pouvez utiliser UNION ALL à la place :

Conclusion:
Dans cet article, nous avons vu comment optimiser les performances de MySQL pour des requêtes de base de données plus rapides et plus efficaces.
Nous espérons que cet article vous a été utile et que vous avez appris quelque chose de nouveau. N’oubliez pas que ces conseils sont généraux et peuvent ne pas s’appliquer à toutes les situations. Il est toujours préférable d’expérimenter et d’adapter ces techniques à vos besoins spécifiques. Bonne chance avec vos requêtes MySQL !